Dati strutturati in Google: quali recepisce? Schema.org, RDFa e microdati
Cercando un po’ in giro per la Rete, ho provato a vedere quali vocabolari vengono interpretati correttamente dallo strumento recente di parsing dei dati strutturati di Google, per iniziare a chiarirmi le idee.
Per far comprendere l’argomento ai neofiti, basta ricordarsi di due elementi per quanto riguarda il dato strutturato:
- sintassi: ad oggi ci sono diversi modi per far digerire a Google dei dati strutturati nella propria pagina, ma questo per ora non sembra un problema. La sintassi consigliata è quella dei microdati, una modalità semplificata non ancora standard, nativa della specifica HTML5. L’altra alternativa è usare RDFa ( specie la sua ultima versione RDFa Lite 1.1 ), la stessa sintassi che usa Facebook con lo standard Open Graph. Nella visualizzazione anteprima del tool di Google, vengono mostrate entrambe.
- struttura ( schemi e vocabolari ): è questo l’argomento spinoso, in effetti. Per ora il consiglio da dare è usare tutto quello presente su schema.org
In tutto questo, se volete un ottimo riassunto, SpazioDati ha fatto un video al Tedx di Brera che chiarirà le relazioni tra molti elementi oscuri ( Semantic Web, Linked Data e molto altro ).
Tornando a qualche esempio pratico, passiamo agli screenshot, recuperato cercando rich snippets con Google Images:

Questa poi merita ancor di più per il volume di vocabolari citati:
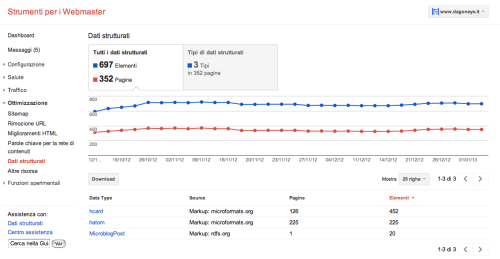
Da queste schermate, si può capire che ci sono diversi vocabolari aggregati:
- quello ufficiale, quindi schema.org
- quello precedente agli sforzi di schema.org, sempre di Google, che è riconducibile a rdf.data-vocabulary.org
- diversi microformati tradizionali
- vocabolari standard riconducibili al mondo del Semantic Web: da SIOC a quello dedicato alle persone ed alle reti sociali ( FOAF ), grazie alla presenza del dominio http://xmlns.com/, a quello SKOS dato il dominio w3.org e il tipo Concept
Insomma: sembra che, anche se non esplicitamente dichiarato, il sistema di parsing vada ben oltre lo schema.org. Poi sicuramente se si desidera la visualizzazione del Rich Snippet, allora è utile solo schema.org, ma questo è ridurre le potenzialità in gioco.
Per fare una prova diretta, sto popolando alcune pagine del blog con sintassi miste: ad esempio con un po’ di dati espressi in RDFa 1.1 Lite per tipizzare alcune fonti, con questo codice qui sotto, che indica come due link siano in realtà due libri.
Ho usato una pagina di test:
Linked Data Patterns (http://patterns.dataincubator.org/book/) Linked Data: Evolving the Web into a Global Data Space(http://linkeddatabook.com/editions/1.0/)Un utilissimo strumento per verificare la sintassi del grafo RDF descritto in RDFa è il sito
http://rdfa.info/play/: infatti basta copiare il testo qui sopra e vedere una specie di grafo con le informazioni salvate.

Ci sono altre esperienze da aggregare? ( specie per quanto riguarda i vocabolari )
Giusto per dare un contributo diretto, ecco la mia esperienza di questi giorni.

Questa è quella di oggi:

Quindi dopo 4 giorni dalla pubblicazione del nuovo sito, ed aver aggiunto i microdata ad ogni post del sito, attraverso il plugin Schema Creator, il risultato è che la pagina di Google dedicata ha aggiunto un nuovo dato, rispetto a quelli precedenti.
Google aggiorna il livello del dato strutturato ogni 4 giorni, guardando anche le date degli andamenti nelle schermate.
Vedremo quanti giorni passeranno per i dati con la sintassi RDFa e vocabolario schema.org.
Nel frattempo, i dati strutturati sarebbero molti, moltissimi di più se solo Google fosse più Linked Data e Semantic Web oriented…
Usando Sindice Inspector si trovano infatti 25 triple di informazione strutturata, usando sempre la pagina di test come esempio:

Fonti:
Italiane
- I Dati Strutturati all’interno del Webmaster Tools
- Schema.org ammette l’utilizzo di RDFa 1.1 Lite sui motori di ricerca
- RDFa 1.1 è ora standard W3C: usato già da Facebook e schema.org
Estere
- Tak Force del W3C : Web Schemas TF
- SemTech, RDFa, Microdata and more…
- HTML Microdata
- SEOs, don’t ignore structured data
- Introducing the Structured Data Dashboard
- Structured Data Dashboard: New Feature in Google Webmaster Tools
- Structured Data Types and Rich Snippets
- An Introduction to Structured Data Markup
